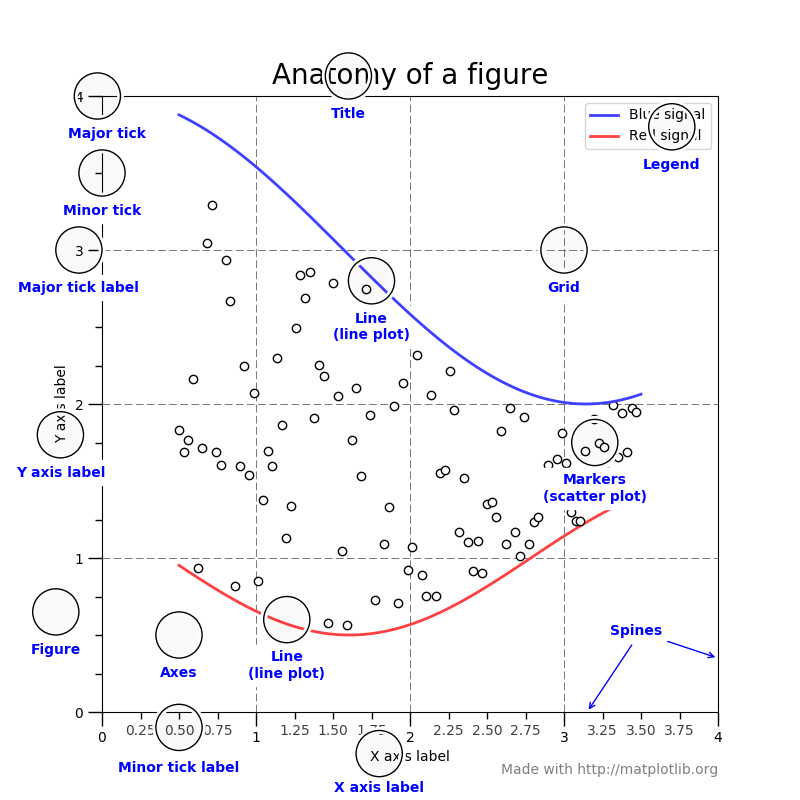
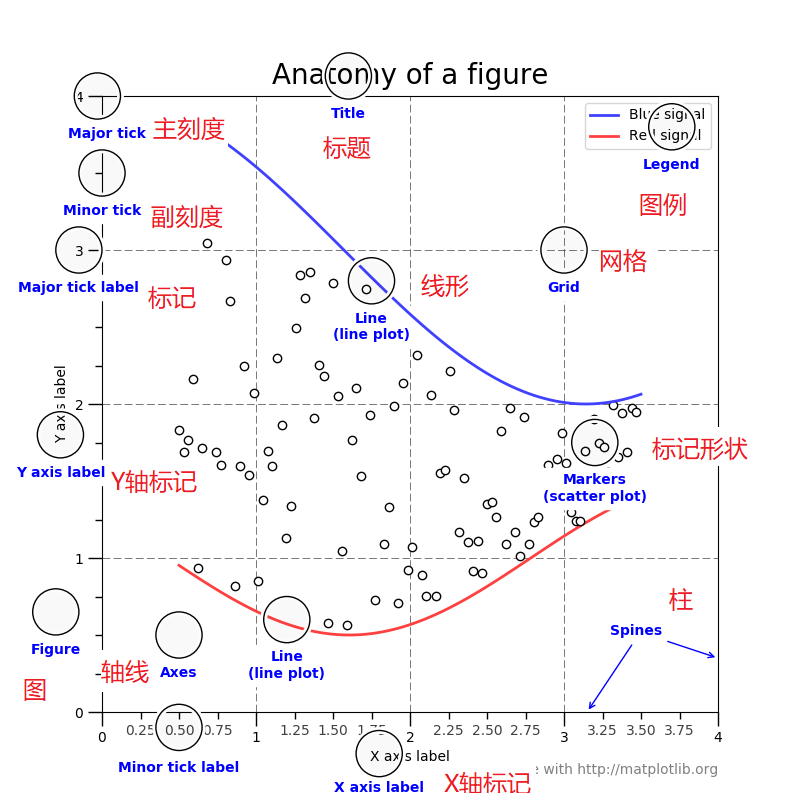
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
|
# -*- coding:utf-8 -*-
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
import os
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['font.family'] = 'sans-serif'
# 解决负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['axes.labelsize'] = 32
plt.rcParams['xtick.labelsize'] = 24
plt.rcParams['ytick.labelsize'] = 24
plt.rcParams['legend.fontsize'] = 20
# 相对路径
project_dir = os.path.abspath('.')
path = project_dir + "\\stack.csv"
out_path = project_dir + "\\request_stack_bar.jpg"
# 全路径
# path = "D:\\request.csv"
# out_path = "D:\\request.jpg"
def main():
# 使用python下pandas库读取csv文件
data = pd.read_csv(path, encoding='utf-8')
# 读取列名为距离误差和时间点的所有行数据
name_list = data.loc[:, '姓名']
january_list = data.loc[:, '一月']
february_list = data.loc[:, '二月']
march_list = data.loc[:, '三月']
april_list = data.loc[:, '四月']
may_list = data.loc[:, '五月']
june_list = data.loc[:, '六月']
july_list = data.loc[:, '七月']
august_list = data.loc[:, '八月']
september_list = data.loc[:, '九月']
october_list = data.loc[:, '十月']
november_list = data.loc[:, '十一月']
december_list = data.loc[:, '十二月']
# 设置画布
plt.figure(num=1, dpi=100, figsize=(24, 32))
# 柱状图
plt.bar(np.arange(len(name_list)), january_list, label=u'1月业绩', tick_label=name_list, fc='r')
plt.bar(np.arange(len(name_list)), february_list, label=u'2月业绩', bottom=january_list, tick_label=name_list, fc='b')
plt.bar(np.arange(len(name_list)), march_list, label=u'3月业绩', bottom=january_list+february_list, tick_label=name_list, fc='g')
plt.bar(np.arange(len(name_list)), april_list, label=u'4月业绩', bottom=january_list+february_list+march_list, tick_label=name_list, fc='c')
plt.bar(np.arange(len(name_list)), may_list, label=u'5月业绩', bottom=january_list+february_list+march_list+april_list, tick_label=name_list, fc='y')
plt.bar(np.arange(len(name_list)), june_list, label=u'6月业绩', bottom=january_list+february_list+march_list+april_list+may_list, tick_label=name_list, fc='m')
plt.bar(np.arange(len(name_list)), july_list, label=u'7月业绩', bottom=january_list+february_list+march_list+april_list+may_list+june_list, tick_label=name_list, fc='WhiteSmoke')
plt.bar(np.arange(len(name_list)), august_list, label=u'8月业绩', bottom=january_list+february_list+march_list+april_list+may_list+june_list+july_list, tick_label=name_list, fc='pink')
plt.bar(np.arange(len(name_list)), september_list, label=u'9月业绩', bottom=january_list+february_list+march_list+april_list+may_list+june_list+july_list+august_list, tick_label=name_list, fc='olive')
plt.bar(np.arange(len(name_list)), october_list, label=u'10月业绩', bottom=january_list+february_list+march_list+april_list+may_list+june_list+july_list+august_list+september_list, tick_label=name_list, fc='navy')
plt.bar(np.arange(len(name_list)), november_list, label=u'11月业绩', bottom=january_list+february_list+march_list+april_list+may_list+june_list+july_list+august_list+september_list+october_list, tick_label=name_list, fc='linen')
plt.bar(np.arange(len(name_list)), december_list, label=u'12月业绩', bottom=january_list+february_list+march_list+april_list+may_list+june_list+july_list+august_list+september_list+october_list+november_list, tick_label=name_list, fc='teal')
# 添加数据标签,也就是给柱子顶部添加标签
x = np.arange(len(name_list))
y1 = np.array(list(january_list.values))
for a, b in zip(x, y1):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y2 = np.array(list((january_list+february_list).values))
for a, b in zip(x, y2):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y3 = np.array(list((january_list+february_list+march_list).values))
for a, b in zip(x, y3):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y4 = np.array(list((january_list+february_list+march_list+april_list).values))
for a, b in zip(x, y4):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y5 = np.array(list((january_list+february_list+march_list+april_list+may_list).values))
for a, b in zip(x, y5):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y6 = np.array(list((january_list+february_list+march_list+april_list+may_list+june_list).values))
for a, b in zip(x, y6):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y7 = np.array(list((january_list+february_list+march_list+april_list+may_list+june_list+july_list).values))
for a, b in zip(x, y7):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y8 = np.array(list((january_list+february_list+march_list+april_list+may_list+june_list+july_list+august_list).values))
for a, b in zip(x, y8):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y9 = np.array(list((january_list+february_list+march_list+april_list+may_list+june_list+july_list+august_list+september_list).values))
for a, b in zip(x, y9):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y10 = np.array(list((january_list+february_list+march_list+april_list+may_list+june_list+july_list+august_list+september_list+october_list).values))
for a, b in zip(x, y10):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y11 = np.array(list((january_list+february_list+march_list+april_list+may_list+june_list+july_list+august_list+september_list+october_list+november_list).values))
for a, b in zip(x, y11):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24)
y12 = np.array(list((january_list+february_list+march_list+april_list+may_list+june_list+july_list+august_list+september_list+october_list+november_list+december_list).values))
for a, b in zip(x, y12):
plt.text(a, b + 0.05, '%.0f' % b, ha='center', va='bottom', fontsize=24, color='AliceBlue')
# 为了让x轴的内容适配展示的长度,请求路径字段比较长,有几十个字符
plt.xticks(np.arange(len(name_list)), name_list)
# 统计图的标题
plt.title(u"XX公司部门每月销售额", size=32)
# 显示图例
plt.legend()
# X坐标-横坐标标题
plt.xlabel(u'部门名称', size=24)
# Y坐标-纵坐标标题
plt.ylabel(u'销售额', size=24)
# 在展示图片前可以将画出的曲线保存到自己路径下的文件夹中
plt.savefig(out_path)
# 显示图像
plt.show()
print("all picture is starting")
if __name__ == "__main__":
main()
|