VCS第三波-VCS的模块工作原理
前言
既然VCS用得多了,原理还是要了解下的,不然定位问题还是很吃力的,知道了集群知识和VCS的工作原理,对日常管理有很大的帮助 转自http://down.51cto.com/data/316764
小结
HAD用于是配合Agent做状态同步的工作进程
LLT用于心跳通讯
GAB用于Cluster内节点的广播,相互协同工作
Fencing用于Cluster管理,相当于脑部,搜集其他部件返回的信息作出决策判断
1、VCS模块简介
HAD: HighAvailability Daemon,是一个后台程序,VCS用来管理Cluster配置信息,响应用户命令,跟踪VCS AGENT传来的各种resource状态变化。
LLT: 是VCS底层的传输协议,同时也负责监控Cluster节点的心跳信息。
GAB: Groupmembership / Atomic Broadcast。 是一个用于管理Cluster成员组成,并在Cluster节点间进行原子广播的内核模块。
I/O Fencing: I/O Fencing 使用一种类似投票的机制,来防止Cluster分裂成两个或多个子群集,它保证在网络异常时,只有一个Cluster可以幸存下来。另外,I/O Fencing还利用SCSI-3协议的persistent reservation来保护共享磁盘上的数据。
2、HAD
High Availability Daemon,是一个后台程序,VCS用来管理Cluster配置信息,响应用户命令,跟踪VCS AGENT传来的各种resource状态变化。并保持每个Node的状态同步,关于状态同步,有个专门的名称,叫做:“replicatedstate machine”,HAD就是这样一个machine。在每个Node上,都有一个HAD进程在运行。
h110121:/->ps-ef|grep had
root 3905 1 0 Feb 16 ? 0:00/opt/VRTSvcs/bin/hashadow
root 3855 1 0 Feb 16 ? 1:13 /opt/VRTSvcs/bin/had
在每个Node上,VCS用户命令,VCSAgent,GUI等组件,通过一个VCS特有的通信协议(叫Inter Process Messaging – IPM)直接与本机上的HAD通信(intra-system communication)。
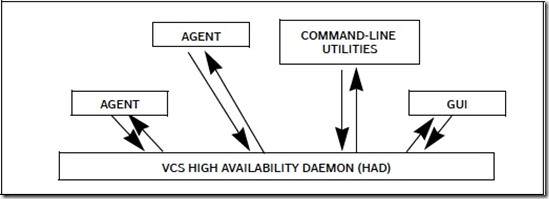 以AGENT为例,它和本机的HAD通信的情形如下:
以AGENT为例,它和本机的HAD通信的情形如下:
 如果用户在某个Node上通过命令或GUI,进行了操作,从而VCS的状态(例如配置信息改变了),或者某个AGENT检测到了 resource状态变化,则命令,或者GUI,或者AGENT,通过IPM将这些变化发送给本地的HAD。然后HAD要负责将这些变化通过网络通知给其 他Node的HAD进程,并且要保证其他节点都正确接收了这些信息,然后其他Node上的HAD进程会在各自的Node上,应用这些变化。由于每个 Node都运行着相同版本的HAD,因此每个Node上的HAD只需要简单地执行与首先发送通知消息的那个Node相同的代码序列。
如果用户在某个Node上通过命令或GUI,进行了操作,从而VCS的状态(例如配置信息改变了),或者某个AGENT检测到了 resource状态变化,则命令,或者GUI,或者AGENT,通过IPM将这些变化发送给本地的HAD。然后HAD要负责将这些变化通过网络通知给其 他Node的HAD进程,并且要保证其他节点都正确接收了这些信息,然后其他Node上的HAD进程会在各自的Node上,应用这些变化。由于每个 Node都运行着相同版本的HAD,因此每个Node上的HAD只需要简单地执行与首先发送通知消息的那个Node相同的代码序列。
前面简略地提及,本地命令,GUI,AGENT通过IPM,与本地HAD通信,统称”intra-systemcommunication”。
更加简略地提及:“HAD要负责将这些变化通过网络通知给其他Node的HAD进程”。通过网络,这个说得太过简略了,实际上这一部分,比想象中复杂得多,因为这忽然就涉及到了复杂的网络通信,并且引出了另外两大模块: GAB 和 LLT。Node之间通过网络进行的通信,统称为“inter-system communication”。
3、LLT
LowLatency Transport protocol,是一个协议。但实际上LLT这个名字在VCS的语境中,包含的内容还要多一些。
3.1 LLT是一个网络协议
LLT从OSI模型的角度来看,是处于第三层,VCS用LLT代替了IP协议,将其用于VCS Cluster内部节点之间进行网络通信的协议。LLT的特点是高效,低延迟。
在我们说到LLT时,往往指的并不是一个协议,人们都喜欢描述一些实际看得见,摸得着的东西,所以,LLT从物理上来说,是“一个内核模块(llt) 一个用户进程(lltd)”。llt内核模块实现了LLT协议,而lltd,作为一个操作系统进程,则会定期调用llt内核模块的 功能,发送心跳信息给其它Node(同时也从其他Node接收心跳信息并保存其它Node的心跳状态)。
3.2 LLT的两大功能
网络传输:在VCS环境中,GAB调用LLT的功能进行实际的网络传输。当然,这是在内核中发生的内部调用。通过LLT进行的网络传输,为什么是 高效的呢? 因为LLT在配置时,允许同时为LLT协议绑定多张网卡(准确的说法其实应该是“绑定多个网络链接”,也可以用“link”这个单词来表示链接的意思),多个网卡对于LLT来说,是对等的地位,是可以进行负载均衡和容错的冗余连接。LLT将数据平均分布在每个网络链路上,如果某个link挂掉了,则使用剩 余的link来传输数据。LLT最多也只能支持8个links。
监控心跳
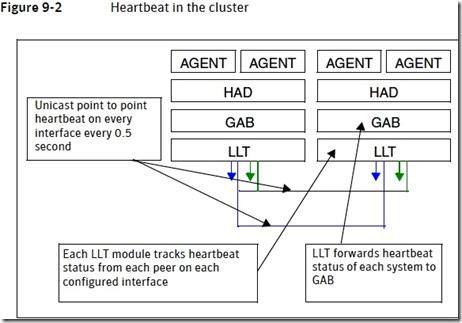
LLT负责监控每个Node的心跳,并负责通知GAB的Membership功能,以便处理这个一些丢失心跳的家伙。
具体地说,就像HAD一样,每个Node上都有一个lltd进程一直在运行。每半秒钟,lltd要通过绑定的links发送自己的心跳信号给其它Node。 LLT模块是知道Cluster中有哪些Node的,它通过unicast单波方式向其他节点逐一发送心跳信号(这里有个问题,将在下文说明)。
心跳信号,大概是这样定义的
- a. 每半秒钟,在每个LLT链接上发送一次
- b. 每个Node上运行的LLT模块,会跟踪每个其他Node(学名叫Peer)在每条LLT链路上的心跳信息
- c. LLT将每个Node的心跳状态信息通知自己Node上的GAB模块的Membership功能
- d. GAB接受到心跳状态信息后,根据该状态信息,决定是否对Membership进行改变
说明一下前面提及的问题:当配置VCS的时候,我们只提供了IP地址或者主机名,作为一个第三层协议的LLT,在以太网中需要知道目标Node的MAC地址才能正确发送数据帧。而MAC地址并没有在安装的时候提供,也没有被安装程序通过ARP协议自动检测并写入配置文件,那么LLT如何发送数据帧 到目标Node呢?实际是这样的:LLT通过数据链路层的广播协议 – 即通过交换机发送一个广播数据帧(目标mac地址为全“1”,ffff.ffff.ffff的帧)进行广播,数据帧中包含Cluster ID(而Cluster ID是安装产品的时候指定的,并且每个Cluster是唯一的),然后局域网中所有拥有同一个Cluster ID的其它Node上的LLT模块,会应答,这样,Node就知道自己Cluster的Node中有哪些Node,以及每个Node的每个link的 mac地址了)。
3.3 心跳信号的传递过程
LLT为什么不能替换IP协议?
LLT在VCS环境中确实可以很高效地传输数据,但它被设计为只在同一个局域网内工作的协议,而不能被路由,因此无法广泛使用作为通用传输协议。正因为 LLT只专注于服务VCS以及Veritas的其他产品,因此它才能高效地集成在VCS产品中。
|
|
虽然没有说强制,但是强烈建议配置至少2条high priority的link,然后至少1条low priority link。
3.4 LLT的查看
|
|
4、GAB
Groupmembership / Atomic Broadcast。如其英文词意反映该模块的功能,用斜杠割开的两部分,就是GAB的两大功能。
GAB的物理存在是一个内核模块,它正如它的名字一样,提供下列两种服务:
4.1 Cluster membership 服务
GAB职责之一,负责处理Cluster的成员变化情况,如果某个Node没有了 心跳,则GAB将其标记为DOWN,然后将其踢出Cluster (我知道这里有点问题,作为一个纯内核模块,GAB是没有后台进程的,那么它是不可能被schedle而得到执行的,也意味着GAB无法定期监控心跳状 态,所以我们只能说GAB负责处理成员变化,而不说它负责监控成员变化。由此可以推断,必然有一个操作系统后台进程要负责监控Node的心跳,并且在检测到心跳丢失后,要负责调用GAB中的Membership功能,要求其进行处理,这就是后面要看到的LLT了)。
4.2 Atomic Broadcast
原子广播功能。这里,不要被Broadcast的字面意思所欺骗,这里所谓的“广播”,其实是局限在Cluster内部几个Node 之间的,并非传统意义的局域网广播。而且,所谓的“广播”其实是一系列Node到Node,点到点的单波组成。
GAB的原子广播功能,为VCS提 供了可靠的消息传递机制(其实不仅仅是VCS,包括Veritas Storage Foundation的很多其他产品,例如CVM,CFS等等)。VCS的HAD,利用GAB的广播功能,将各种变化(或称之为消息),通过网络传递给所有其他Node上的HAD进程。GAB广播的原子性,将保证这些消息能够被正确传递到每个Node,如果整个传递过程发生了错误,则HAD会roll back到变化前的状态,因此才有了Atomic的说法。
4.3 集群节点(4个node)中HAD的广播过程
广播首先从发生变化那个Node开始,该Node上的HAD进程,要求本机内核中的GAB的Atomic Broadcast功能,在整个Cluster范围内广播一个变化消息。
而GAB模块的Atomic Broadcast功能,则根据Cluster配置开始列举Cluster中的剩余Node,并一一进行点对点的单波。
当目标机器上的HAD收到了这个消息之后,会发送一个回执,确认消息发送成功。
在本例中,如果3个Node中的某一个(因为网络故障或其它原因)没有收到消息,从而没有发送回执给源机器上的GAB,则整个广播过程失败,第一个Node的HAD会rollback所发生的变化。
前面介绍了HAD和GAB,但实际的底层消息传递,仍然停留在“通过网络”这个模糊的概念上面,一般情况下看到“通过网络”这样的描述,很容易产生其它联想,如TCP/IP,UDP,SOCKET等等。实际上,LLT才是VCS真正负责底层网络通信的模块。用户程序(包括GUI/COMMAND/AGENT),HAD,GAB,LLT之间的层次关系如下图所示:
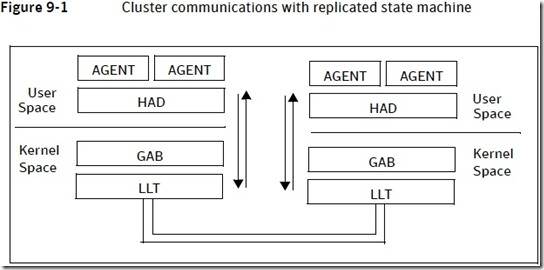 Gab不是一个进程:
Gab不是一个进程:
|
|
Gab驻留在内核里,为内核服务:
|
|
gabconfig-a命令列出GAB的端口信息
|
|
这是一个状态良好的VCS GAB端口注册信息
4.4 GAB和LLT结合的优势
GAB和LLT并非业界广泛使用的协议,而是专门针对VCS的底层架构,LLT直接构建在链路层之上,因此LLT的实现比TCP/IP协议精简,但效率更 高。然而GAB和LLT只为Veritas产品提供服务,这也是为什么后面的讲解中,会发现有一些模块间紧密耦合的情形(例如LLT不仅仅是一个网络层协 议,而且还是心跳接收者,LLT知道有个GAB模块,并且会主动与GAB交互心跳信息)。
前面说到,GAB的两大功能之一,是Atomic Broadcast,可以在Cluster范围内进行广播。虽然名字是Broadcast,而在GAB内部,却是通过LLT对广播目标逐一进行unicast。
TCP/IP的广播,是对同一网段的所有机器进行广播,这个过程利用了链路层交换机的广播功能。
GAB广播,是对VCS Cluster内部的所有Node进行广播,这个过程没有利用链路层交换机的广播功能。
GAB所谓的广播,其实是有目的,点对点的单波,对所有Node一一进行一次数据传输,然后收到对方的回执,则一次单波结束,单波的次数多了,也就成了广播……。
需要GAB广播功能的子产品(操作系统进程,或内核模块),首先调用本地GAB模块的对应功能,要求为自己保留一个GAB端口,这个过程叫做注册,这个注册信息会被GAB广播到Cluster的节点,让其他节点也能看到同样的GAB端口注册信息。
然而,归根结底,所有的网络通信,都是位于进程间互相通信,这些互相通讯的进程,运行在不同Node上。对于GAB来说,每个Node上的同样功能的的进程,会注册同一个端口。例如,每个Node上的had进程,都会使用GAB端口h,然后通过端口h,广播had自己的消息,在Node间互 相update信息。
与IP协议类似,GAB广播,是“进程:端口-> 端口:进程”的广播。但是,这里的端口,并非传统意义的TCP/IP端口,而是GAB自己定义的一个数据结构,由GAB内核模块来维护。
4.5 GAB的查看
现在来看一下前面的那条命令:
|
|
4.6 GAB端口对应表
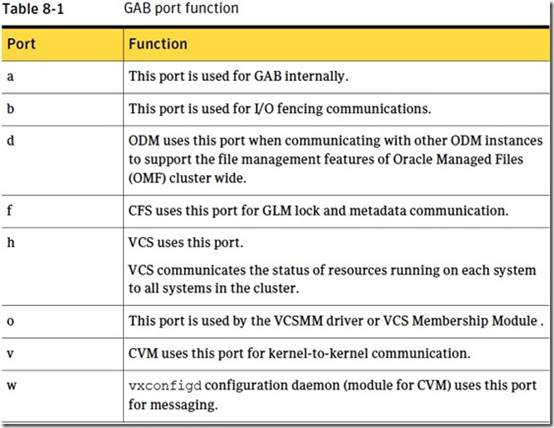 好了,有了前面的基础,下面的事情就好讲了。接着说一下GAB是如何维护Cluster Membership的(这也是GAB的两大功能之一)。
好了,有了前面的基础,下面的事情就好讲了。接着说一下GAB是如何维护Cluster Membership的(这也是GAB的两大功能之一)。
Clustermembership,实际就是说GAB能及时更新每个端口的“Node map”,然后其他的进程或内核模块可以询问GAB,以得到当前的Membership。看下面这个输出:
|
|
这里的分号“;”是一个占位符,表示Node 0本来是在Cluster里面的,但现在它挂了,所以给它留个位置,等它恢复正常后,仍然在这个位置填上0,表示0号Node回来了。
GAB的Group Membership功能,由GAB自身提供,当一个VCS Cluster启动时,GAB自己会注册并占用一个端口,就是端口“a”。GAB通过这个端口来为其他模块提供服务,并且也用于所有Node的GAB模块 进行状态同步。其它模块通过GAB的端口a,可以向GAB询问当前的Membership状态。比如had,必须通过GAB获取当前的Membership,如果Membership发生了改变,则它进行相应的处理,例如对ServiceGroup做Faiover。
GAB可以管理多个Membership,但是端口“a”上的membership,是特殊的,因为它代表的是Cluster Node Membership,出现在任何其他membership里的Nodes,都必须先出现在端口a上,因为这个membership表示每个物理的 Node是否处于Cluster中,如果物理Node都不在,那么其他端口上也不可能出现这个Node了。并且,端口a上的Nodemap由GAB亲自注册并维护。端口名称“a”本身,也表现出其特殊地位。这个Membership因此又有一个特殊的名字,叫做“seed membership”,相对应这个名称,GAB初始化端口a的过程,就叫做”seeding“。
4.7 Cluster Membership的初始化过程
4.7.1 准备
准备好2个node的cluster,集群正常运行
|
|
4.7.2 关其中一个node
shutdown其中一个,然后reboot另外一个,预计这个reboot的node启动之后,无法seeding,因为另一个node彻底down掉,达不到预定node数量。node启动后,GAB端口a没有打开
|
|
4.7.3 观察had
然后观察had的运行状况,had在运行,但它不会执行任何HA相关的管理功能
|
|
4.7.4 检查
然后在node上执行 gabconfig -c -x,对它进行手工seeding,它会启动一个不完整的Cluster,即只有1个Node的cluster。端口a的node map中没有”;“号占位符,表示这个Cluster只有一个Node
|
|
4.7.5 端口检查
等1分钟,再看GAB端口,随着seed membership的建立,其他的软件模块都会相应地向GAB注册自己的端口,并开始工作:
|
|
4.7.6 启动
将那台shutdown的机器启动起来,新启动的Node可以自动加入Cluster。因为重启Node的过程中,会尝试自动Seeding,这时候的Node数量,已经满足要求。
|
|
5、Fencing
5.1 Fencing模块的功能
集群node上都有一个内核模块叫做”vxfen“,它负责仲裁。在5.1以及之前的版本,Fencing模块只能通过一组叫做coordinate disk的共享磁盘来进行仲裁(从StorageFoundation 5.1开始,Fencing也可以使用第三方IPS服务器进行仲裁了)。
5.2 Fencing模块主要动作
Cluster正常操作时,Fencing模块在coordination disk上注册自己所在的这个node 。
Clustermembership变化时,两个subcluster通过竞争coordination disk的控制权,来抢夺(race)重组cluster的资格。最少要有3块coordination disk,必须是基数,抢到其中大部分的subcluster,获得重组的权利,另外一个subcluster自动退出。Coordination disk可以使用DMP磁盘。
5.3 Coordination Points
就是指coordination disk或者IPS服务器。coordination必须支持SCSI-3协议的persistent reservation特性,以便于fencing模块register自己,eject其他node,这是抢夺控制权的技术手段。 coordination disk不能用于存放用户数据,因此越小越好。从/etc/vxfentab可以看到当前的coordination disk有哪些。IPS服务器是位于网络上的一个仲裁服务器,通过网络为Fencing模块提供仲裁服务。
抢夺Coordination Disk的过程,都是由Fencing模块利用了SCSI-3协议的Persistent Reservation功能来实现的,后面简称SCSI-3 PR 。之所以叫做Persistent,是因为Reservation信息不会由于系统重启而丢失(不会由于SCSI总线reset而丢失)
5.4 SCSI-3 PR
registrationand reservation。 SCSI-3 Registration允许主机在某个磁盘设备上注册一个自己的key。而多个主机注册的key,形成了一个membership,并且建立了一个 reservation,设置reservation的类型,一般是WERO – Write Exclusive Registrants Only。
WERO设置只允许在其上注册过key的主机对该磁盘进行写操作,key当然是保存在存储硬件的controller中,而不是写在disk上 。对于某一个磁盘设备,只有一个reservation,但是可以有多个registrations。 使用 SCSI-3 技术,如果想禁止某个主机写入某块磁盘,只需简单地删除掉那个主机所注册的key。
只有注册过key的主机,才能删掉其他主机的key。这个过程叫做”eject the registration of another member“。删掉别的主机的key的命令是”preempt and abort”,这是一个原子操作。被“eject”掉的主机,由于失去了key,因此无法再去eject别的主机 在WERO模式下,之前被eject掉的主机,可以再次注册自己的key然后又具有了eject别人的key的能力。
5.5 Fencing的工作过程
fencing启动时:
Coordination磁盘放在一个DG中,配置fencing的时候需要手工创建这个DG,有个名字叫做“Coordination Disk Group”,有个特殊的标志“coordinator=on”(# vxdg -o coordinator=on init)
配置fencing的时候要将Coordinator DG的名字放在/etc/vxfendg文件里面
永远不需要import这个Coordinator DG
vxfen有个启动脚本,例如HPUX: /sbin/init.d/vxfen,启动脚本读取/etc/vxfendg文件获得Coordinator DG的名字,然后通过vxvm命令读取DG中的成员,以及成员磁盘的每条路径,然后写入/etc/vxfentab文件
DG中的每个Coordinator disk的每条路径,都在/etc/vxfentab里面有一条记录,例如:有3个Coordinator Disk,每个Disk有2条路径,则/etc/vxfentab里会有6条记录
fencing内核驱动程序开始启动,读取/etc/vxfentab,使用其中的特殊设备文件路径,查询到磁盘的序列号,并构建内存中的列表
fencing通过GAB端口b检查fencing的membership,如果没有其它成员,则表示自己是第一个启动fencing的node,进而认定自己的coordinatordisk配置是正确的
如果端口b上已经有其他成员,说明自己不是第一个node,则向LLT ID最小的一个node请求coordinatordisk的配置信息,最小LLT ID那个node回复这个请求,发送coordinator disk的序列号列表给请求信息的node ,如果返回结果与自己在内存中构建的列表一致,这个node就加入cluster,如果返回结果与自己的列表不一致,就发生错误,这个过程能保证同一个cluster里的所有node都使用同一套coordinator disk 。
5.6 Fencing模块检查是否有脑分裂的可能性存在
这个检查的原理是:在coordinator disk上注册过key的node,也应该在GAB端口b的membership中出现。否则,说明自己可能是在不同的一个subcluster里。于是 fencing模块读取coordinator上的所有key,然后与自己的GAB端口b上的member进行比对,如果不一致,说明当前可能是一个脑分 裂的情形,于是fencingdriver打印warning信息到console和syslog,停止执行。
如果所有的检查都通过了,则每个node各自的fencing模块向每个coordinatordisk的每条路径注册自己的key,每个node的在每条路径上注册的key的内容是一样的,是根据各自的LLT ID构建的(例如:LLT ID 0 = A)
运行过程中:
在正常情况下,每个node的Fencing模块会在所有的path上,向Coordination Disk注册了自己的key。同一个node的每条连接Coordination Disk的path都注册同一个key
每个key的内容,是基于每个node的LLTID的,例如LLT ID 0的node,注册的key的内容可能是“A”
于是在正常情况下每个Coordination Disk的每条path上都存在每个node的key。
当Cluster成员发生变化时,每个节点的GAB将失效的node标记为DOWN。然后将自己隔离出去的node列表通知给Fencing模块,Fencing模块开始仲裁
在剩余的Node中,拥有最小的LLT ID的那个node,代表自己这个membership中的其他node去竞争Coordination disk。这个node的Fencing模块将尝试对每个Coordination Disk通过SCSI-3 PR的preempt and abort命令,去eject隔离列表中的node的key。如果在某个Coordination Disk上成功eject所有的外部key,就意味着获取了一个disk的控制,获取到超过半数的Coordination disk的控制权,就成功赢得了竞赛
在一般情况下,被隔离的node是真的down掉了,竞争很快就会结束,因为没有竞争……
在脑分裂的情况下,每个subcluster中的拥有最低LLT ID那个node,代表其他node去竞争
回顾前面的SCSI-3 PR的简介,只有注册过key的node,才能去eject别的key,而且preempt and abort操作具有原子性,因此如果node能抢先eject掉别的node的key,则被eject的那个node就无法反攻了。这个机制保证了每次竞 争只有一个胜利者
如果一个node赢得了race胜利,就通知自己所代表的其他node胜利的消息,于是这个subcluster可以继续存活。这个消息也被通知给GAB。
竞争失败的node,由于无法面对信任过自己的朋友,选择了自杀(或者说成是“vxfen模块会主动触发一个system panic”),它所代表的其他node,会意识到这个panic,然后也纷纷panic,并重启(老大都自杀了,小弟也没有活路了)。
重启后的node,会尝试seeding,假设重启后故障消除了(node可以与/etc/gabtab文件里规定个数的node交换心跳),则可以继续加入cluster。
如果重启后仍然没有消除故障,(node无法与/etc/gabtab文件中规定个数的node交换心跳),则seeding失败,需 要手工干预。注意,手工干预不是说要管理员去手工seed,而是应该去排除故障。在Fencing enable的情况下,手工seeding虽然会成功,但是在尝试加入cluster时,fencing模块会去检查Coordinate Disk上的key,如果没有自己的key,会发生“mismatch”错误,vxfen不会继续执行,进而HAD也不会启动。
如果fencing被人disable了的情况下,在这种情况下的手工seeding可能会造成“人工脑分裂”。
5.7 Fencing模块竞争coordinator disk的策略
原则是尽量保留大多数node,node数量高于51%的subcluster,优先级较高,node数量较小的subcluster,被延迟一会儿,然后才开始竞争
原则是尽量让同一个subcluster赢得所有的coordinator disk。赢得第一个disk的subcluster,优先级较高,输掉第一个disk的subcluster,被延迟一会儿才继续参与下一块磁盘的竞 争。这样是为了避免3个或多个subcluster竞争时,各自赢得了一个coordinator disk,打成了平手。
不干净地关闭cluster,例如整个机房同时断电,会在coordinator disk上留下很多残留的key,这些key在fencing启动时,会导致fencing认为出现了脑分裂而无法启动。这时需要人工的干预,用 vxfenclearpre清除掉残留的key 。
- 原文作者:Anttu
- 原文链接:https://anTtutu.github.io/post/2017-05-14-vcs3/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。